How Multi-Modal Annotation Improves Computer Vision Performance

Artificial Intelligence Has Made Significant Progress in Enabling Machines to Understand the World Through Visual Perception. From Autonomous Vehicles and Intelligent Surveillance Systems to Robotics and Healthcare Imaging, Computer Vision Models Are Becoming Increasingly Sophisticated. However, as Real-World Environments Become More Dynamic and Complex, Relying on a Single Data Modality—Such as Images Alone—Is No Longer Sufficient.
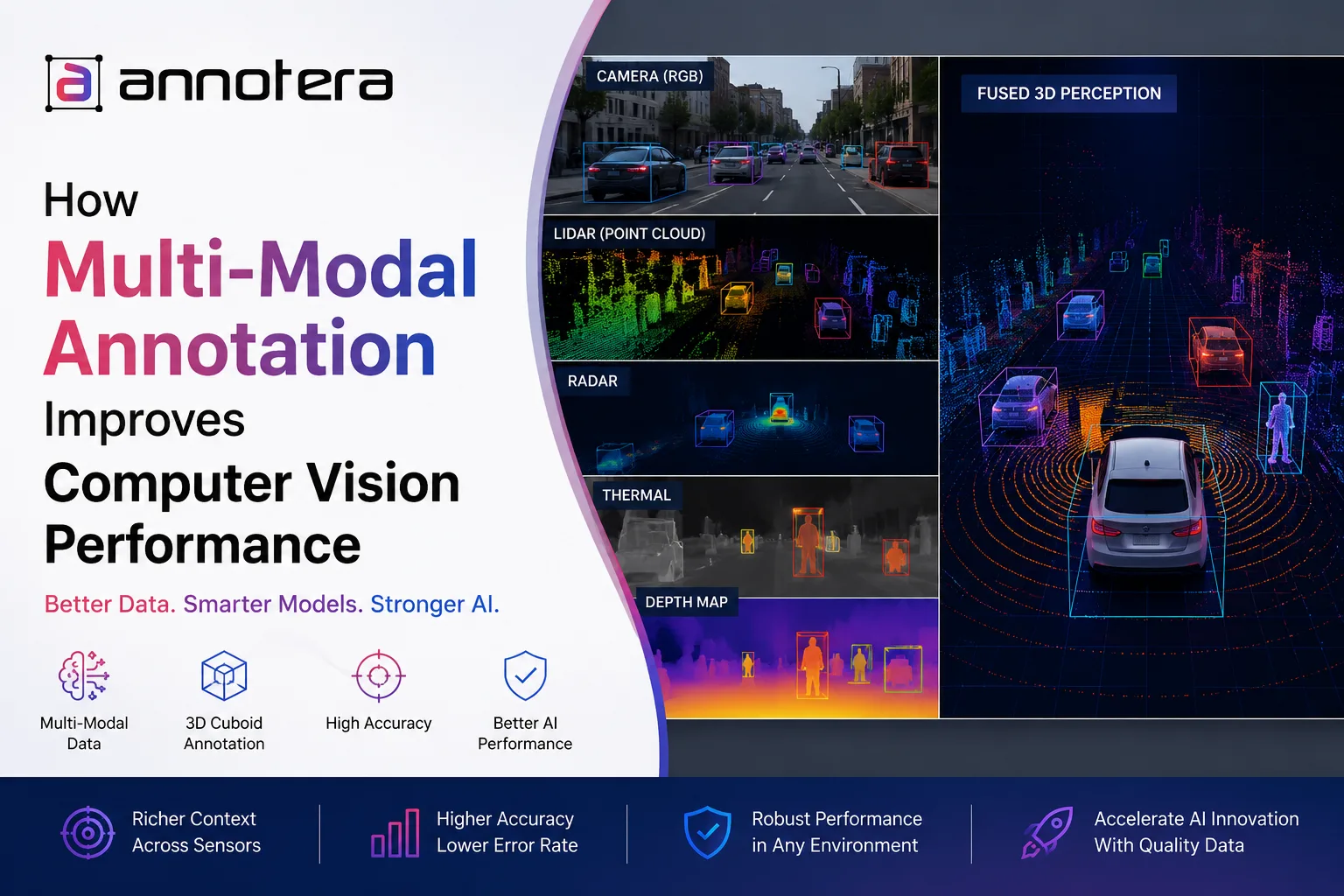
Today's AI systems are trained using multiple data sources, including RGB images, LiDAR point clouds, radar, thermal imagery, videos, audio, GPS data, and sensor metadata. This shift has made multi-modal annotation one of the most critical components of high-performing computer vision systems.
At Annotera, we help organizations build reliable AI by delivering high-quality multi-modal annotation services that combine human expertise with scalable quality assurance. As a trusted data annotation company, we support enterprises developing next-generation perception systems across autonomous driving, robotics, healthcare, retail, and industrial automation.
What Is Multi-Modal Annotation?
Multi-modal annotation is the process of labeling and synchronizing multiple data types collected from different sensors so AI models can understand the relationships between them.
Instead of annotating only camera images, annotation teams label and align information across:
- RGB images
- Video sequences
- LiDAR point clouds
- Radar data
- Thermal images
- Depth maps
- GPS and IMU sensor information
For example, an autonomous vehicle simultaneously captures images from cameras, 3D point clouds from LiDAR, radar reflections, and vehicle telemetry. Annotators identify the same pedestrian, vehicle, or obstacle across every modality, creating consistent ground truth for AI training.
This comprehensive approach enables machine learning models to perceive environments more accurately than using any single sensor alone.
Why Single-Modal Computer Vision Falls Short
Real-world environments constantly challenge computer vision systems.
Examples include:
Low-light conditions
Heavy rain and snow
Fog
Occlusions
Motion blur
Reflective surfaces
Dense traffic
A standard RGB camera may struggle to detect pedestrians at night, while LiDAR can accurately capture object geometry regardless of lighting. Thermal cameras can identify living beings in darkness, and radar performs reliably during adverse weather.
Multi-modal annotation teaches AI models how these complementary sensor inputs relate to one another, significantly improving perception accuracy.
How Multi-Modal Annotation Improves Computer Vision
1. Better Object Detection
Annotating objects across images, LiDAR, radar, and video enables AI to detect objects that might be partially hidden or difficult to recognize in one modality.
For example:
LiDAR captures precise distance.
Cameras capture texture and color.
Radar measures velocity.
Combining these annotations produces significantly stronger object detection models.
2. Improved 3d Scene Understanding
Autonomous vehicles and robotics require machines to understand depth, object orientation, and spatial relationships.
This is where 3D cuboid annotation becomes indispensable.
Rather than simply drawing 2D bounding boxes, annotators create accurate three-dimensional cuboids around vehicles, pedestrians, cyclists, traffic signs, pallets, warehouse shelves, and industrial equipment.
These annotations allow AI systems to estimate:
Distance
Object dimensions
Orientation
Movement trajectory
Collision risk
The result is more reliable environmental perception and safer autonomous decision-making.
3. Stronger Sensor Fusion Models
Modern perception systems depend on sensor fusion.
Multi-modal annotation aligns corresponding objects across different sensor streams, enabling AI models to learn relationships between modalities instead of treating each independently.
This synchronization substantially improves robustness under challenging environmental conditions.
4. Reduced False Positives
Single-camera models frequently mistake shadows, reflections, or visual artifacts as real objects.
When annotated LiDAR or radar data confirms object existence, AI learns to distinguish actual obstacles from visual noise.
This dramatically reduces false alarms in safety-critical applications.
5. Better Performance in Adverse Weather
Rain, fog, smoke, dust, and darkness often degrade image quality.
However:
Radar penetrates fog.
Thermal imaging detects heat signatures.
LiDAR captures structural information.
Multi-modal annotation enables AI to continue making accurate predictions even when one sensor experiences degraded performance.
Industries Benefiting From Multi-Modal Annotation
Several industries now rely on multi-modal datasets to build production-grade AI.
Autonomous Vehicles
Autonomous driving systems integrate:
Cameras
LiDAR
Radar
GPS
IMU
Accurate synchronized annotation enables reliable lane detection, pedestrian recognition, traffic sign understanding, and collision avoidance.
Robotics
Warehouse robots and industrial automation systems require precise localization and object recognition.
Multi-modal annotation improves robotic picking, navigation, obstacle avoidance, and manipulation accuracy.
Smart Surveillance
Security systems increasingly combine CCTV footage with thermal imaging and audio analytics.
Multi-modal datasets improve threat detection while minimizing false alerts.
Healthcare
Medical AI often combines:
MRI
CT scans
X-rays
Clinical notes
Annotated multi-modal datasets improve diagnostic accuracy and clinical decision support.
Retail
Retail analytics platforms combine video, shelf images, RFID signals, and customer movement data to improve inventory monitoring and customer behavior analysis.
Challenges in Multi-Modal Annotation
Although highly valuable, multi-modal annotation introduces several operational challenges:
Synchronizing multiple sensor streams
Maintaining annotation consistency across modalities
Handling large volumes of LiDAR point clouds
Managing temporal alignment in video sequences
Ensuring quality across millions of annotation instances
These complexities require experienced annotation specialists, robust quality control workflows, and scalable project management.
Many AI companies therefore choose image annotation outsourcing and broader data annotation outsourcing to access trained annotators, advanced tooling, and faster project execution without compromising accuracy.
Why Human Expertise Still Matters
Despite advances in AI-assisted labeling, human annotators remain essential for resolving ambiguity.
Complex scenes involving occlusion, unusual object interactions, edge cases, and sensor inconsistencies still require expert judgment.
As computer scientist Fei-Fei Li famously stated:
"The quality of your data determines the quality of your AI."
Human reviewers validate AI-generated labels, correct errors, and continuously improve dataset quality, creating the reliable ground truth necessary for production-ready computer vision systems.
Why Choose Annotera for Multi-Modal Annotation?
Annotera delivers enterprise-grade annotation services tailored for advanced AI perception projects.
Our capabilities include:
Multi-modal sensor annotation
High-quality image and video labeling
3D cuboid annotation for LiDAR and sensor fusion datasets
Human-in-the-loop quality assurance
Scalable global annotation teams
Domain expertise across automotive, robotics, healthcare, retail, manufacturing, and geospatial AI
Whether you're training next-generation autonomous systems or building industrial computer vision applications, our experienced specialists deliver consistent, accurate, and scalable annotations designed to maximize AI model performance.
Final Thoughts
Computer vision is rapidly evolving beyond single-image understanding toward rich, sensor-fused perception systems capable of interpreting the world with greater accuracy and resilience. Multi-modal annotation forms the foundation of this evolution by creating synchronized, high-quality datasets that enable AI models to learn from complementary sources of information.
As organizations continue investing in perception AI, choosing an experienced data annotation company becomes a strategic advantage. Through expert data annotation outsourcing, reliable image annotation outsourcing, and precise 3D cuboid annotation, businesses can accelerate AI development while improving model accuracy, safety, and real-world performance.
At Annotera, we help enterprises transform complex multi-modal data into trusted AI training datasets that power the next generation of intelligent computer vision solutions.
0 comments
Log in to leave a comment.
Be the first to comment.